How to hack a company by circumventing its WAF for fun and profit – part 2
So far, one of the most successful and visited posts in our blog has been this one. Following the interest of readers on the topic, we have decided to publish more contents like that. What we will be doing periodically in these spaces is to recount a few stories extrapolated from circumstances that happened for real. We had a lot of fun by living them in first person during penetration testing sessions, red team operations or well deserved bug bounties. We hope you will have too.
The “single-encoded-byte” bypass
Some time ago, we have been contacted to perform the revalidation of a RCE web vulnerability that could be triggered by visiting a URL similar to this:
https://victim.com/appname/MalPath/something?badparam=%rce_payload%
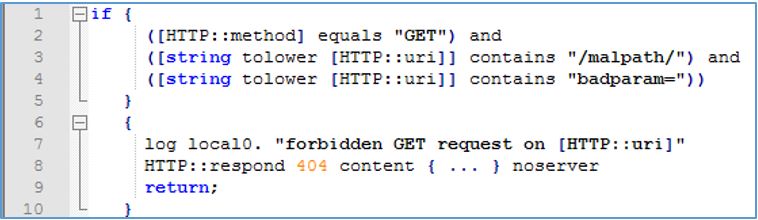
The application was hosted behind a Big-IP device with ASM (Application Security Manager) module enabled, a layer 7 web application firewall (WAF) available on F5’s BIG-IP platforms. To react immediately and not leave the solution exposed to the internet, the network engineers thought well of deploying a custom WAF rule to protect the endpoint before a formal fix was actually introduced in the application’s code. Our role consisted of investigating the effectiveness and robustness of this rule which looked like something similar to this:
The meaning of it was that in case a HTTP GET request had been intercepted (line 2) and the lowercase-converted URI contained both the strings “/malpath/” and “badparam=” (lines 3 and 4), the request would have been logged first (line 7) and then blocked by returning the HTTP error 404 to the client (line 8).
Actually, after deploying the custom WAF rule, by visiting the URL:
https://victim.com/appname/MalPath/something?badparam=%rce_payload%
…we receive the 404 HTTP error, meaning that the rule is working and the WAF is doing properly its job.
However, by reading the F5 documentation we discovered that the directive “HTTP::uri” (lines 3 and 4) returns the URI of the request without first fully decoding it! So if we visit the URL:
https://victim.com/appname/%4dalPath/something?badparam=%rce_payload%
…with “%4d” being the URL-encoded form of the character ‘M’, this is what happens:
- The WAF intercepts the GET request. The URI in there “
/appname/%4dalPath/something?badparam=%rce_payload%” is first entirely converted to lowercase because of the “tolower” function in the WAF rule, and becomes “/appname/%4dalpath/something?badparam=%rce_payload%”.
- Then the URI is looked for the presence of the strings “
/malpath/” and “badparam=”. Anyway, in the first case the string “/%4dalpath/” we sent does not match with the string “/malpath/” in the WAF rule (line 3), which hence is not hit.
- Once the WAF control is bypassed, the HTTP request reaches the backend server where the URI canonicalization and decoding processes take place. So the request containing the URI converted from “
/appname/%4dalPath/something?badparam=%rce_payload%” to “/appname/MalPath/something?badparam=%rce_payload%” is passed to the target web application which in turn serves it.
- The “
%rce_payload%” is now executed and produces its effects (opening of a reverse shell, invocation of an operating system command, etc…)
Here the lesson learnt of the day is: always ensure that URI is decoded before comparing and checking it. Absolute lack of URI decoding is very bad. The usage of “contains” keyword in a WAF rule is even worse.
Partial URL decoding = full bypass
A couple of days later we were called back again to carry out the revalidation of the revalidation (lol) as the fix in the application code was taking more time than expected.
This time visiting both the URLs:
https://victim.com/appname/MalPath/something?badparam=%rce_payload%
and
https://victim.com/appname/%4dalPath/something?badparam=%rce_payload%
returned the 404 error page. In simple words, the WAF blocked us.
Then we attempted to double encode the letter “M” of “/Malpath/” with the sequence “%254d”. The final URL to visit was:
https://victim.com/appname/%254dalPath/something?badparam=%rce_payload%
Nothing. The web application firewall was blocking this request too. The reimplementation of the WAF rule now looks something like this:

Here the lines from 15 to 24 are equivalent to the lines 1-10 of the previous rule’s version. However this time the strings “/malpath/” and “badparam=” are checked against a variable called “$decodeUri” (lines 17 and 18) and not “HTTP::uri” as done before. What is this and where does it come from? Actually the lines from 1 to 14 are defining its content. In simple terms the “$decodeUri” variable is just the URI of the request (“[HTTP::uri]” at line 2). It is URI-decoded at most “max” times (with “max” being defined at line 4) through a “while” loop (lines 9-13) by using a counter variable (“cnt” declared at line 5). The loop is interrupted in case there are no more encoded characters left or the iteration in the cycle has occurred for “max” times (with “cnt” increased during each iteration).
To better understand what’s going on here, it could be helpful to browse this page and perform fourfold percent-encoding of the letter “M” by writing the sequence “%252525254d” into the text box. Now press over the “Decode” button (see picture below) for four times and during each pause see what happens. Have you seen it? This is exactly what the WAF rule above is doing with our URI.

So to bypass it, we have simply visited the following URL:
https://victim.com/appname/%252525254dalPath/something?badparam=%rce_payload%
On reception the WAF decodes the URI as follows:
- (1st iteration of the loop):
/appname/%2525254dalPath/something?badparam=%rce_payload%
- (2nd iteration of the loop):
/appname/%25254dalPath/something?badparam=%rce_payload%
- (3rd iteration of the loop):
/appname/%254dalPath/something?badparam=%rce_payload%
- (4th iteration of the loop):
/appname/%4dalPath/something?badparam=%rce_payload%
When the WAF rule quits the loop, the request’s URI is set to “/appname/%4dalPath/something?badparam=%rce_payload%“. Again, as in the previous case, the string “/malpath/” (line 17 of the WAF rule) does not match with the one in the URI “/%4dalpath/”, so the WAF let the request pass through. The control is bypassed once more and the effect is always the execution of “%rce_payload%”. GAME OVER for the second consecutive time.
One could think: “Ok, but this is a stupid mistake! Just fire these monkeys preteding to be security guys!”. This is not totally true as the “-normalized” option, that undoubtedly simplifies the life of network engineers, can be adopted only with the most recent versions of iRules, leaving as a unique option the creation and deployment of a custom rule which is notoriously an error-prone process. However, it is still surprising how many sources out there are publicly advertising these flawed examples, even in the official F5 documentation (watch the screenshot below).

For copy & paste supporters this kind of “code snippets” are like honey. Don’t get us wrong. We have nothing against copy & paste, except when this practice is performed in cybersecurity without understanding what is being done. In such circumstances copy&paste has been a countless number of times the root cause of many serious security vulnerabilities.
But let’s switch back to our main story! After the identification of the new issue the fix was quick (see the added part below).

Basically, following the “while” cycle (lines 9-13 in the picture at the beginning of this paragraph), the content of the WAF rule was updated with an “if” branch. It checks, at the end of the loop, if the value of the counter variable “cnt” is equal to the value of the “max” variable. In case it is, this means that the “while” cycle was interrupted while there were still characters to decode left in the URI. As we don’t want to process a request still containing encoded characters, the WAF rule responds with a 404 error, preventing the activation of the malicious payload.
Wrong assumptions … any gumption?
Most misconfigurations and bypass techniques at WAF level are not linked to technical problems or bugs afflicting the device itself, but wrong assumptions in the logic of its rules.
Our story may have had a happy ending at this point. Two revalidations had already revealed some flaws in the web application firewall’s configuration and finally a pretty tough WAF rule had been implemented, decently decoding the URI. To make it short, in a certain moment somebody realizes that the same vulnerability could have been exploited with a HTTP POST request. The WAF rule provided protection only against GET requests and a new modification to it was needed. So, after the umpteenth change we were called back again to verify that this time everything was working as expected.
To cover both exploitation cases (GET and POST) the network engineers thought to apply a fix by deleting the line 16 of the WAF rule:
if ([HTTP::method] equals “GET”) [...]
Without that line the check on the URI would have been performed on any HTTP request, regardless of the method specified. It could have been an elegant solution if had worked…but can you spot the problem here? Take yourself few seconds before to answer. Well, when the URL below is browsed:
https://victim.com/appname/MalPath/something?badparam=%rce_payload%”
the following HTTP request is issued:
GET /appname/MalPath/something?badparam=%rce_payload% HTTP/1.1
[...]
If after discovering that the GET method is blocked at WAF level an attacker attempted to circumvent it via POST, the following request would be instead issued:
POST /appname/MalPath/something HTTP/1.1
[other HTTPheaders]
badparam=%rce_payload%
Would the “%rce_payload%” be triggered this time, given all the premises above? Yes, it would. Why? The answer is in the lines 17 and 18 of the WAF rule, shown below once more.

Let’s compare the content of the attacker’s POST request with the logic of the custom rule. In this case, at line 17 the fully decoded and lowercase-converted URI contains the string “/malpath/”. True. However the line 18 stems from an incorrect assumption. The parameters of a POST request reside in the HTTP body and not in the query string! The line 18 of the WAF rule is instead checking for the presence of the string “badparam=” in the “$decodedUri” variable which in the case of the attacker’s POST request returns the string “/appname/MalPath/something”. For sake of clarity, the WAF rule is not checking the string “badparam=” where it should, so the rule is bypassed.
Officially the revalidation of the revalidation of the revalidation was last round of check to be confident enough that the WAF rule implemented was providing the level of security desired against this web vulnerability. It took 1 week to tune up the custom WAF rule and then, suddenly, few more days later, it was removed because in the meantime the application code had been patched 😀
If it helps to repeat that once more, WAF virtual patching is ok if you need a bit of extra time before fixing a serious vulnerability, but it must not be abused. One week of exposure to RCE is a huge period of time for motivated attackers. The only way to sleep peacefully is to solve your problems at code level and patch it, patch it, patch it as soon as possible! Probably would have been worth from the beginning to dedicate all the resources to patch the application code than struggling to implement a working WAF rule by trial and error.
That’s all for today. Other stories like this will be published in future. So stay tuned and continue to follow us!

Hey! Red Timmy Security will be at Blackhat Las Vegas this year too! Check out our trainings!
Practical Web Application Hacking Advanced 1-2 August and 3-4 August 2020.






Gloss